Twitter-analysoinnista on näköjään tullut tämän blogin ydintoimintaa. Mutta uteliaan ihmisen on vaikea vastustaa sen helppoutta, ajankohtaisuutta ja monipuolisuutta. Jotta asiat pysyvät mielenkiintoisina niin lukijoille kuin kirjoittajallekin niin otamme pari uutta menetelmää käyttöön analyysimme tueksi.
Ensiksi harrastan ns. sentiment analysisia, jonka voinee suomentaa mielipiteiden louhinnaksi tai mielipideanalyysiksi. Tässä käytetty algoritmi on hyvin yksinkertainen; twiitit käännetään Microsoftin käännösohjelman avoimen rajapinnan avulla englanniksi, jonka jälkeen sanoja verrataan Hun ja Liun mielipidesanastoon. Jos twiitissä on enemmän positiivisiksi kuin negatiiviseksi miellettyjä sanoja, luokitellaan se mielipiteeltään positiiviseksi. Ja toisin päin. Jos kumpaankaan sanalistaan ei saada osumia tai niitä on yhtä paljon, on mielipide luokaltaan neutraali. Metodi jättää luonnollisesti paljon kritisoitavaa alkaen suomesta englantiin kääntämisen epätarkkuudesta ja merkitysten muutoksista päättyen sarkasmiin ja sanojen luontaiseen monitulkintaisuuteen. Puhumattakaan siitä, että miten tulkitaan negatiiviseksi luokiteltua twiittiä tapahtumasta, jonka perusvire ei ole kovin positiivinen? Kyllä Wittgenstein kääntyy haudassaan.
Toinen menetelmä keskittyy etsimään erilaisia diskurssityyppejä luokitellen sanoja toisilleen läheisiksi. Eli jos esimerkiksi "ollaan", "lapista, "hallitus", "voi" ja "vapista" esiintyvät jatkuvasti yhdessä eri twiiteissä, luokitellaan ne omaksi ryhmäkseen. Tähän käytetään kahta menetelmää. Toinen perustuu adjacency matrixiin (läheisyysmatriisiin?) ja toinen edellisessä postauksessa esiteltyyn hierarkiseen klusterointiin.
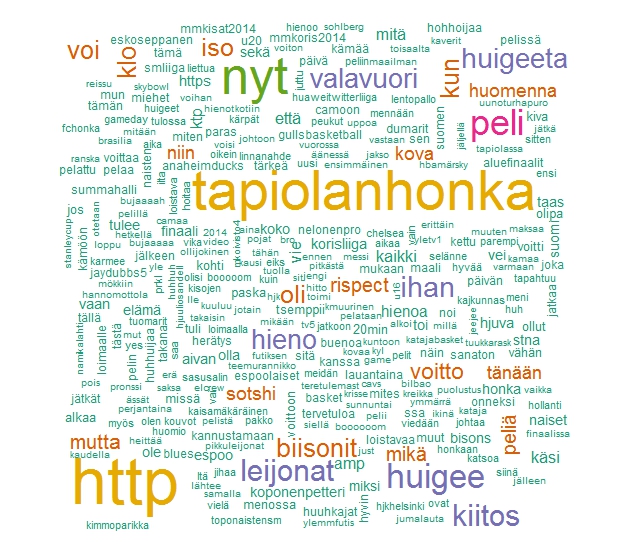
Aloitetaan mielipiteen louhinnalla. Positiivisiksi twiiteiksi luokiteltiin yhteensä 1290 twiittiä, neutraaleiksi 3107 ja negatiivisiksi 3603. Alla niihin liittyvä vertailusanapilvi:

Positiivisessa sanapilvessä mainitaan Petteri Poukka, hyi. Ja en tiedä mihin liittyy sanat "isot" ja "tissit". Mutta mutta! Positiivissa puhutaan duunareista sekä kätilöistä, mainitaan bussikuljetukset ja tunnelma ja ilmeisesti rauhallisesti meni myös tapahtuma. Oikeudenmukaisuus ja tasapuolisuus kuuluvat myös positiivisiin.
Mielenilmaus oli selkeästi neutraali termi. Toisaalta neutraaleihin on lipsahtanut paljon twiittejä, jotka kannattivat tai vastustivat tämän päivän lakkomielenilmaussuurtapahtumaa. Ainakaan Alkosta ei ole neutraalista puhuttu, tuskin hallituksesta tai ay-liikkeestäkään.
Yhteenvetona voitaneen todeta, että ennakko-odotuksista huolimatta twiittien luokittelualgoritmi teki vähintään välttävää ellei jopa kelvollista työtä.

Yllä olevasta sekavasta kuviosta nähdään, kuinka tietyt sanat esiintyvät yhdessä. Ison massan lisäksi on oikeastaan havaittavissa vain kaksi hieman muista poikkeavaa diskurssia. Yksi on Petteri Poukan Internetiäkin vanhempi mömmöm-95-Jutirillaa-hassuttelu ja toinen ilmeisesti johonkin random-Keskustanuoreen alekoivistoon kiteytyvä aikuiset-kitisee-nuoret-maksaa-velan-leikataan-diskurssi. Hieman enemmän sanoja sisältävässä versiossa miniminin ja iPadin kanssa esiintyi vielä PC-lakko ja Amazon. Mikä sitten on pc-lakko? Pitää varmaan kysyä piraateilta.
Värien mukaan myös muita ryhmittymiä voisi löytyä, mutta tuosta massasta niitä ei voi bongata. Siirrytään siis hierarkiseen klusterointiin.
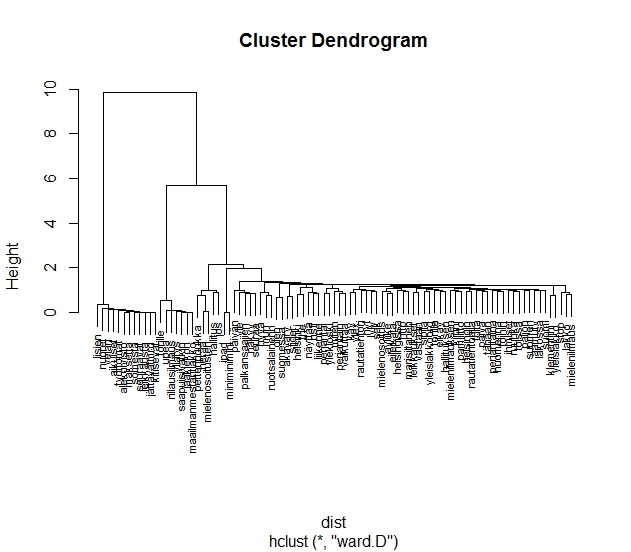
Omana selkeänä isona klusterina erottuu ensiksikin edellisestäkin kuviosta bongatut Petteri Poukan elämääkin väsyneemmät hakamussuttelut sekä kepunuoridiskurssi. AY-liike esiintyy vähemmän yllättäen "eileikata"-tagin kanssa ja "leikkaukset" esiintyy sanan "vastaan" kanssa. Yle "seuraa" ja "näkyy" palkansaajien yhteydessä, Hesaria kiinnostaa enemmän liikenne ja Helsinki. Ammattiliittopomot Sture Fjäder ja Lauri Lyly esiintyvät ammattiliittojensa Akavan ja SAK:n kanssa yhdessä, SAK huomattavasti lähempänä "eileikata" ja "AY-liike"-tageja. Mutta miten klementiini liittyy yleislakkoon? No olemalla vallaskumousbloggari.
Katsotaan vielä muutaman sanan korrelaatiot. "Eileikata" korreloi voimakkaasti jostain syystä feminismin ja naisunionin kanssa. "Leikkausten" kanssa esiintyy usein "turhaa", "pikkumaista" ja "itkemistä". SAK:n kanssa esiintyy "ulostulon", "lakkopolitiikan" ja "työnuuden" lisäksi "tuhoaa".
Alustava johtopäätös tästä kaikesta on, että twitter-kansa siis näyttää hieman enemmän tuominneen tämänpäiväisen mielenilmauksen kuin tukeneen sitä. Mutta myös ymmärrystä ja kannatusta mielenosoittajille löytyi huomattava määrä. Täytyy toisaalta muistaa laajempia johtopäätöksiä tehdessä, että Twitter ei ole millään tavalla edustava otos kansasta, vaan siellä on yliedustettuna toimittajat, poliitikon alut sekä narsistiset social media power playerit.
Keskustelu jatkuu aiheen ympärillä vielä varmasti pitkään ja sosiaalisen median vaikuttajilla tulee näppäimistö laulamaan niin puolesta kuin vastaan, ehkä myös päinvastoin. Kokoomusnuorten tai Vasemmistonuorten diskurssin ennustamista varten ei tarvitse tehdä naiivia bayesilaista luokittelija-algoritmia tai muitakaan malleja, joten ehkä tämä riitti tästä aiheesta.





















{kind=link}