Blogin kirjoittamisen epämiellyttävin osuus on, no, kirjoittaminen. Älkää käsittäkö väärin, ei se epämiellyttävää ole. Minulla ei ole koskaan ollut kauheaa luomisen tuskaa kirjoittamisen yhteydessä tai tyhjän paperin pelkoa.
Se ei vain usein ole niin hauskaa kuin itse datan kanssa näpräily. Kun itse on kertaalleen saanut hauskan näpräilyn jälkeen datasta enemmän tai vähemmän innostavia oivalluksia, on niistä kaikelle kansalle kirjoittamisen hauskuus suoraan verrannollinen löydösten kiinnostavuuteen. Ja aina sen hauskuus jää jälkeen varsinaisen data-analyysin tekemisestä.
Miten siis optimoida hauskan koodinäpräilyn ja enemmän tai vähemmän miellyttävän kirjoittamisprosessin suhde? Vastaus on yksinkertainen.
Shiny.
Shiny on R:n kirjasto, jolla voi kirjoittaa erilaisia interaktiivisia applikaatioita. Sovelluksen voi jakaa kaikkien käyttöön erilaisten palvelimien kautta. Tällöin jokainen sovellusta käyttävä voi itse tutkia dataa osaamatta itse sen kummemmin koodata tai tuntematta tilastotiedettä, sovelluksen asettamien reunaehtojen puitteissa.
Koska kansalaisdatatieteilijöiden nousu on tällä hetkellä yksi data-alan isoista trendeistä, on vain soveliasta, että minäkin tarjoan lukijoille välineet tehdä löytöjä sen sijaan, että tekisin löydöt lukijoiden puolesta.
Siispä, saanen esitellä ensimmäisen Shiny-applikaationi!
Applikaatio käyttää hyväkseen Tilastokeskuksen tarjoamaan Paavo-rajapintaa, joka sisältää postinumeroalueittaista avointa dataa. Paavoa käytettiin vanhassa blogipostauksessani hyödyksi, mikä onkin Shiny-sovellukseni idean pohjana. Sovelluksessa voidaan tutkia halutun kunnan postinumeroalueita kahden muuttujan perusteella (yhteensä valittavana 13 muuttujaa). Applikaatio piirtää sirontakuvion, jossa havainnot väritetään kahteen tai useampaan väriin taustalla pyörivän k-means klusterointialgoritmin perusteella. Paavon data on vuodelta 2014, lukuunottamatta rakennustietoja (mökkien lukumäärä ja keskimääräinen asunnon pinta-ala) ja väestötietoja (keski-ikä ja asukasmäärä)
Ja ei muuta kuin tutkimaan! Ideoita uusista Shiny-applikaatioista saa lähettää, toteutan niitä osaamisen ja käytettävisen olevissa ajan mukaan.
Perinteisempien blogi-postauksien ystävien ei kuitenkaan tarvitse huolestua. Aion myös jatkossa kirjoittaa perinteisempien data-kikkailujeni tuloksia auki.
Otsikon kysymykseen muuten vielä oikea vastaus: ei kumpikaan, shiny-appsit ovat vaan pirun siistejä!
sunnuntai 18. joulukuuta 2016
lauantai 17. joulukuuta 2016
Paljon liikuntaa, huono terveydentila ja viinaa - eurooppalainen kansanterveys eurooppalaisten kertomana
Aivan Euroopan kovimpia ryyppymiehiä ei täällä kuitenkaan olla; Tanskan huolettomat hyggeilijät vievät voiton myös tällä mittarilla mitattuna. Maailman onnellisimpien on helppo avata viinipullo. Mittarina alla olevassa kartassa käytetään vähintään kerran kuukaudessa kovaan humalaan ("heavy episodic drinking" käyttäen Eurostatin virallista termistöä) itsensä juovien osuutta.
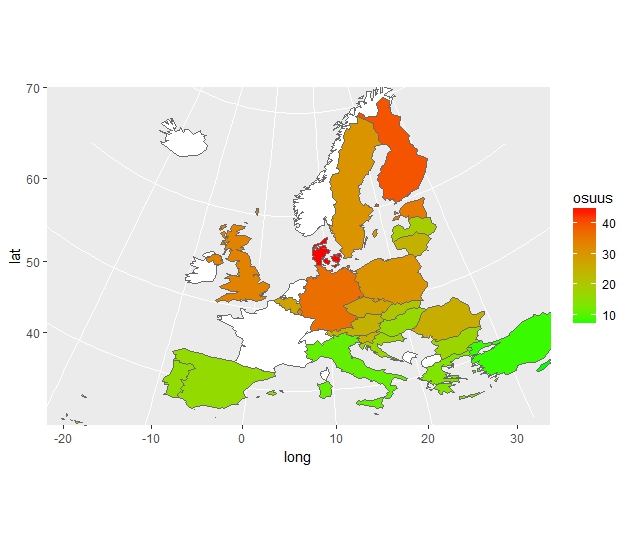
Vaikka Suomen tuleva alkoholilainsäädännön uudistus nostaa taas kerran suomalaisen alkoholipolitiikan ja juomiskulttuurin esille, niin itsessään kuin suhteessa ympäröivään maailmaan, niin tässä postauksessa ei aiheesta enempää jutella.Varsinaista terveystieteellistä data-analyysiäkään ei harrasteta. Sen sijaan tässä käsitellään EU-valtioiden terveysprofiileja näiden maiden kansalaisten itse ilmoittaman tiedon perusteella. Miten erilaiset terveysindikaattorit korreloivat keskenään mitattuna valtiotasolla? Ja mitkä valtiot muistuttavat eniten toisiaan terveysprofiililtaan?
Aineistona käytetään Eurostatin lukuja vuodelta 2014. Aineiston lopullinen koko on valitettavasti vain 24 maata, sillä kaikista EU-maista ei dataa ole saatavilla. Valittuina muuttujina on jo mainittu vähintään kerran kuukaudessa kovempaa juomista harrastavien osuus, ylipainoisten (BMI > 25) osuus, melko tai hyvin masentuneiksi itsensä kokevien osuus, 5 tai enemmän hedelmä ja/tai vihannesannosta päivässä syövien osuus, päivittäin tupakoivien osuus, hyväksi tai erittäin hyväksi oman terveydentilansa kokevien osuus, vähintään 150 minuuttia viikossa urheilevien osuus sekä pitkäaikaissairaiden osuus. Muistaakseni. Tuhosin vahingossa koodit sen jälkeen kun tein kuvat. Hups. Joka tapauksessa, alla kuvio korrelaatioverkostosta muuttujien kesken.

Valtiotasolla kova alkoholin kulutus on siis vahvasti kytköksissä säännölliseen liikkumiseen ja vähäiseen tupakointiin. Maissa, joissa ihmiset liikkuvat paljon, ihmiset myös kokevat olevansa sairaampia. Ylipainisemmissa maissa ihmiset kokevat olonsa terveemmäksi. Paljon tupakoivissa maissa masennusta on vähemmän. Viskipaukun tai viiden kanssa nautitaan hiukopalaksi virkistävä mandariini.
Kuten näemme, ihmisten terveysaiheisten vastausten aggregointi valtiotasolle ei tuota mikrotasolta odotettavissa olevia riippuvuussuhteita. Sen sijaan aineisto antaa mielenkiintoisen läåpileikkauksen eurooppalaisiin kulttuureihin ja elämäntapoihin.

EU-maat terveysprofiilin verkostograafissa
Yllä nähdään, että miten eri maat ovat linkittyneitä toisiinsa näiden terveysprofiilien perusteella. Mittarina käytetään euklidista etäisyyttä. Suomelle läheisiä ovat siis Tanskan ja Ruotsin kaltaisten pohjoismaiden lisäksi köyhät Romania ja Bulgaria. Myös Puolaan, Kreikkaan (EL), Liettuaan ja Italiaan linkki on verrattain voimakas.
Jos kuviota tulkitsee laajemmin niin näyttää siltä, että EU: sta löytyy terveysprofiililtaan samankaltaisten maiden ydin sekä joukko oman tien kulkijoita, joiden terveysprofiili ei valituilla mittareilla ole hirveän lähellä mitään toista maata. EU: ta ei siis voi terveyskentässä esimerkiksi jakaa selkeisiin pohjoinen/etelä tai itä/länsi-blokkeihin.
Tämä oli vain pintaraapaisu aiheeseen. Olisi mielenkiintoista tutkia, että miten ihmisten kyselytutkimuksissa itseilmoittamat mittarit korreloivat makrotasolla valtioiden mitattavissa oleviin terveysindikaattoreihin (esimerkiksi myyty alkoholin, tupakan ja vihannesten määrä per asukas, sairaspoissaolojen määrä). Jos EU-maiden tulisi unionin tulevaisuuden kannalta lähentyä niin poliittisesti kuin taloudellisesti toisiaan niin ihmisten kannalta oleellisena voitaisiin pitää myös terveydellistä lähentymistä; ja niin, että esimerkiksi ylipainoisten osuus laskisi, ei kasvaisi.
keskiviikko 9. marraskuuta 2016
Jenkkijytky Twitterissä: miten Trumpin voittoon reagoidaan?
Vuosi 2016 tullaan muistamaan poliittisten protestien vuotena, vuotena jolloin poliitikot heittivät faktat roskakoriin ja vaalit ratkaisi epämääräiset tunteet. Donald Trumpin valinta on itsessään suuri onnettomuus tuodessaan maailman voimakkaimman valtion johtoon miehen, josta emme oikeasti tiedä, että minkälaista politiikkaa hän tulee aidosti ajamaan seuraavan neljän vuoden ajan. Mutta vielä huolestuttavampaa on se iso kuva, johon Trumpin voitto asettuu; Trumpin valinta on jälleen yksi uusi isku liberaalin, avoimen, suvaitsevaisen maailman arkkuun, jota esimerkiksi Unkarin Orban, Puolan PiS ja brexit ovat jo pelkästään vuonna 2016 kovasti heikentäneet.
Kampanja-Trumpin kaikkia lupauksia presidentti-Trump ei tietenkään pysty täyttämään. Lähtökohtaisesti voimme kuitenkin odottaa ainakin ympäristöarvojen polkemista, luultavasti Pariisin sopimuksesta vetäytymistä, protektionistista kauppamuurien pystyttämistä sekä arvaamatonta ja epävakautta lisäävää ulkopolitiikkaa. Maailman ja planeetan ympäristö, talous ja turvallisuus tulevat kärsimään, enemmän tai vähemmän.
En aio tehdä monimutkaista data-analyysiä tai huolella kirjoitettua poliittista analyysiä. Satoja minua parempia kirjoittajia on kirjoittanut ja kirjoittaa aiheesta parempia artikkeleja. Teen tässä vain nopean analyysin, että millä fiiliksin Trumpin voitto otettiin vastaan. Omassa kuplassanihan Trumpin voittoa lähinnä kauhisteltiin. Syystä.
Aineistona on noin 1600 twiittiä, joissa mainitaan sana "Trump" (en tiedä miksi Twitterin apista ei minulle isompaa massaa tällä kertaa suotu). Teen aineistolle syuzhet-paketin avulla sentiment analysis-tarkastelua eli tutkin twiiteissä esiintyviä tunnetiloja.
Kun kaikki alle 0-AFINN-arvon negatiivisiksi ja yli nollan positiivisiksi, luokkien frekvenssit ovat seuraavat:
Twitterissä siis lievä enemmistö on positiivin mielin Trumpin voitosta. Ei ihme, voittihan hän vaalitkin.
Tässä vielä sanapilvi, jossa erotellaan negatiivisiksi ja positiiviksi luokiteltujen twiittien yleisimmät sanat.

"Shit". Ei lisättävää. No, neljä vuotta on lyhyt aika tuhota maapallo ja alle kolmekymppisten äänissä niin Clinton kuin Bremain olisivat olleet massiivisia voittajia.
Kampanja-Trumpin kaikkia lupauksia presidentti-Trump ei tietenkään pysty täyttämään. Lähtökohtaisesti voimme kuitenkin odottaa ainakin ympäristöarvojen polkemista, luultavasti Pariisin sopimuksesta vetäytymistä, protektionistista kauppamuurien pystyttämistä sekä arvaamatonta ja epävakautta lisäävää ulkopolitiikkaa. Maailman ja planeetan ympäristö, talous ja turvallisuus tulevat kärsimään, enemmän tai vähemmän.
En aio tehdä monimutkaista data-analyysiä tai huolella kirjoitettua poliittista analyysiä. Satoja minua parempia kirjoittajia on kirjoittanut ja kirjoittaa aiheesta parempia artikkeleja. Teen tässä vain nopean analyysin, että millä fiiliksin Trumpin voitto otettiin vastaan. Omassa kuplassanihan Trumpin voittoa lähinnä kauhisteltiin. Syystä.
Aineistona on noin 1600 twiittiä, joissa mainitaan sana "Trump" (en tiedä miksi Twitterin apista ei minulle isompaa massaa tällä kertaa suotu). Teen aineistolle syuzhet-paketin avulla sentiment analysis-tarkastelua eli tutkin twiiteissä esiintyviä tunnetiloja.
Kun kaikki alle 0-AFINN-arvon negatiivisiksi ja yli nollan positiivisiksi, luokkien frekvenssit ovat seuraavat:
negatiivinen positiivinen
749 845
Jos taas otetaan raaoista sentimenttiarvoista keskiarvo, on lopputulos 0.124.
Twitterissä siis lievä enemmistö on positiivin mielin Trumpin voitosta. Ei ihme, voittihan hän vaalitkin.
Tässä vielä sanapilvi, jossa erotellaan negatiivisiksi ja positiiviksi luokiteltujen twiittien yleisimmät sanat.

"Shit". Ei lisättävää. No, neljä vuotta on lyhyt aika tuhota maapallo ja alle kolmekymppisten äänissä niin Clinton kuin Bremain olisivat olleet massiivisia voittajia.
maanantai 31. lokakuuta 2016
Sukupuolten palkkatasa-arvo makrotason tarkastelussa
Tänään maanantaina 31.10 vietetään jälleen STTK:n järjestmämää naisten palkkapäivää eli päivää, jolloin naisten vuoden ansiot on jo "kasassa". Päivää voisi kutsua myös kansalliseksi tilastojen väärintulkitsemispäiväksi, sillä reilun 80 sentin arvoisen "naisten euron" luoma mielikuva miehille samasta työstä mystisesti sukupuolen perusteella maksettavasta palkkapreemiosta on täysin virheellinen.
Todellisuudessa miesten ja naisten saama palkkatulo samoista tehtävistä samanlaisella kokemuksella on lähes identtinen. Ei siis ole olemassa mitään 20 prosenttiyksikön mieslisää, jolla miehet tienaisivat samoista töistä enemmän kuin naiset. Sen sijaan sukupuolten välillä on eroja esimerkiksi ammattirakenteessa sekä tehdyissä työtunneissa, joiden vaikutukset saatuun palkkaan näyttäytyvät puusilmäisessä tarkastelussa sukupuolesta johtuvina palkkaeroina. Naisten ja miesten välinen ero ansiotuloissa on todellinen ja sisältää myös aitoja sukupuoli-perusteisia ongelmakohtia, joihin pitää puuttua. Mutta yksinkertaistamalla palkkaero binääriseksi kahden luokan väliseksi vertailuksi ilman muiden palkkaa selittävien muuttujien huomiointia kohdistuu huomio aivan vääriin asioihin.
Keskustelu palkkaerosta on siis usein aivan liian yksinkertaistettua eikä siinä huomioida mitään muuta kuin sukupuoli. Se on yhtä hedelmällistä kuin keskustella suomalaisten ja maahanmuuttajataustaisten rikollisuudesta käyttäen pelkästään etnisyyttä selittävänä tekijänä (maahanmuuttajat ovat esimerkiksi kantaväestöä nuorempia ja huono-osaisempia, mikä selittänee suuren osan havaituista eroista). Palkkaan vaikuttaa suuri määrä erilaisia muuttujia ja mikäli sukupuolten aitoa palkkaeroa halutaan tarkastella, tulee nämä taustatekijät ensiksi vakioida. Toisaalta jokainen tilastotiedettä vähänkin ymmärtävä tietää, että tarkasteluun valitut muuttujat muuttavat aina hieman tuloksia ja tehtäviä johtopäätöksiä, kuten Mika Malirantakin ansiokkaasti yllä linkkaamassani jutussa mainitsi. Siltikin mediassa paljon julkisuutta saaneen Milja Saaren väitöskirjassaan esittämä väite on huteralla pohjalla ja mielestäni suhteellisen heikko perusta tieteellisen tutkimuksen pohjaksi:
Mikrotasolla miesten ja naisten välistä palkkaeroa on tutkittu monen eri mallin voimin useaan kertaan, joista yksinkertaisin mallinnus on valitettavasti tunnetuin pelkän sukupuolen huomioiva"naisen euro"-päätelmä. Sen sijaan en ole aiemmin juuri törmännyt aiheen käsittelyyn rakenteellisella makrotasolla, jossa ihmisen asuinympäristö vaikuttaa myös sukupuolten väliseen tuloeroon. Tässä postauksessa tutkin miesten ja naisten palkkaeroa yksittäisten yksilöiden sijaan alueellisella makrotasolla; missä ja minkälaisissa kunnissa sukupuolten välinen ero palkkatuloissa on suurin?
Suomi on tunnetusti jakautunut voimakkaasti mies- ja naisaloihin ja ammatillinen segregaatio on EU:n kärkipäätä. Ammattijakauma on myös varsin poikkeava Suomen eri alueiden kesken, sillä esimerkiksi Kainuun perukoilla on huomattavasti vähemmän asiantuntijatehtäviä kuin suurissa kaupungeissa. Myös toimialarakenne tai esimerkiksi väestöllinen huoltosuhde ("vanhuskunnissa" tarvitaan enemmän naisvaltaisia hoitajia, joilla on yleisesti alhaiset palkat) ovat tekijöitä, jotka voivat makrotasolla johtaa suuriinkin kunnittaisiin eroihin eri sukupuolten ansiotasossa.
Aineistona minulla on Verohallinnon data päätoimen palkasta luontoisetuineen vuodelle 2014 (jaan vuoden kokonaispalkkatulot kahdellatoista, jotta saan approksimaation kuukausipalkasta) ja selittävinä muuttujina käytän logaritmia verovelvollisten määrästä (väestön määrän sijaan, logaritmi väestöjakauman vahvan vinouman vuoksi) sekä Tilastokeskukselta väestön koulutusmittaria (VKTM), työttömyystasoa, naisten työllisyysastetta, kuntien välistä muuttotasetta, väestöllistä huoltosuhdetta, ulkomaalaisten osuutta väestöstä sekä yritysten liikevaihtoa henkilöittäin.
 Miesten ja naisten välinen tuloero kunnittain Suomessa 2014
Miesten ja naisten välinen tuloero kunnittain Suomessa 2014
Kun tuloerojen jakautumista tutkitaan alueittain niin huomataan, että hieman yllättäen tuloerot ovat suurimmat isoissa kaupungeissa ja niiden kehyskunnissa. Varsinkin Lapista löytyy toisaalta alueita, joissa naiset tienaavat miehiä paremmin. Kartan perusteella naisten suhteellinen asema miehiin nähden on paras syrjäseuduilla, joissa myös sukupuolten jakauma on vinoutunein miesten hyväksi ja jossa taloudellisia mahdollisuuksia on vähiten.
Naiset muodostavat yhä suuremman osan koulutetusta, urbaanista väestöstä, mutta suurituloisimmat ammatit näyttävät yhä olevan miesten hommia. Sen sijaan miehistyvällä maaseudulla vähät työpaikat jakautuvat tasaisemmin sukupuolten kesken, eikä kumpikaan sukupuoli saa suuria summia. Tutkitaan seuraavaksi miten valitut selittävät muuttujat korreloivat tuloerojen kanssa.
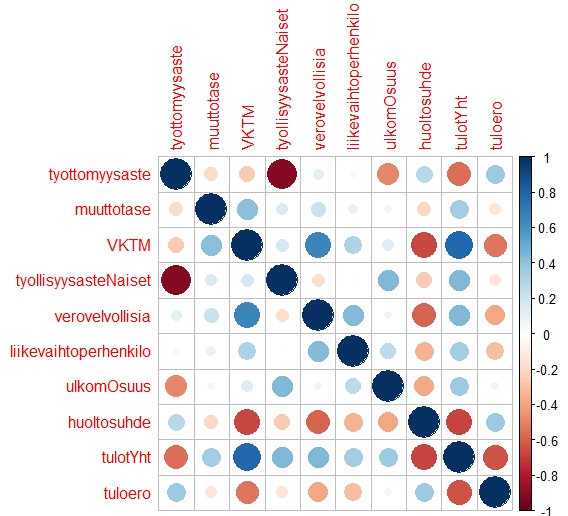
 Korrelaatiomatriisi selittävistä muuttujista ja tuloerosta.
Korrelaatiomatriisi selittävistä muuttujista ja tuloerosta.
Korrelaatiomatriisista nähdään, että odotetusti selittävät muuttujat korreloivat melko voimakkaastikin keskenään, mikä tulee aiheuttamaan regressiomallissa kollineariteettiongelmia.
Miesten naisia suurempien tulojen kanssa korreloi voimakkaimmin yllä nähdyn kartan perusteella odotetusti kaikkien veronalaisten tulojen mediaani sekä väestön koulutustaso. Korkean tulotason ja koulutuksen sekä dynaamisen liike-elämän kunnissa myös sukupuolten väliset tuloerot venähtävät miesten hyväksi. Korkean työttömyyden ja heikon väestöllisen huoltosuhteen kunnissa taas naiset ovat suhteellisesti paremmin palkattuja. Ulkomaalaisten osuudella, muuttotaseella tai naisten työllisyysasteella ei näytä olevan juuri yhteyttä palkkatason eroon.
Kahden muuttujan välisten korrelaatioiden tarkastelu yksistään tarjoaa kuitenkin vääriä johtopäätöksiä jo mainittujen kollineariteettiongelmien vuoksi. Parempia johtopäätöksiä saadaan tehtyä, kun muiden selittävien muuttujien vaikutus palkkaeroon vakioidaan. Siksipä lopuksi mallinnan naisten ja miesten välistä palkkaeroa lineaarisen regression avulla. Skaalaan kaikki muuttujat yhteismitallisiksi, jotta muuttujien suhteellista selitysvoimaa ja tarkkuutta voidaan vertailla.
Ylläolevasta regressiotaulukosta nähdään, että malli on tilastollisesti merkitsevä ja selittää jopa 61 % miesten ja naisten alueellisessa palkkaerossa havaitusta vaihtelusta. Vakiotermi ei mallissa ole tilastollisesti merkitsevä, kuten ei myöskään väestön koulutustaso ja väestöllinen huoltosuhde. Nämä kaksi muuttujaa kuitenkin korreloivat vahvasti palkkaeron kanssa, mutta niiden korrelaatio myös muiden selittävien muuttujien kanssa vei niiden selitysvoiman kun työttömyysaste ja muut tekijät vakioitiin. Sen sijaan ulkomaalaisten osuus kunnan väestöstä esiintyykin voimakkaasti selitysvoimaisena muuttjana muiden selittävien muuttujien ollessa vakioitu. Muiden muuttujien ollessa vakioitu, korkeampi ulkomaalaisten osuus tarkoittaa naisille suhteellisesti parempaa palkkaa.
Myös muuttotase muuttuu tilastollisesti merkitseväksi selittäjäksi, kun muut selittävät muuttujat vakioidaan. Muuttovoittokunnissa naisten palkkaus vaikuttaisi olevan suhteellisesti parempaa. Kun muuttotasetta korreloitiin pelkän palkkaeron kanssa, vaikutussuhde oli päinvastainen. Muun ollessa vakiona myös naisten korkeampi työllisyysaste vaikuttaa voimakkaasti palkkaeroihin naisten kannalta suotuisasti. Tämä on hyvin looginen johtopäätös, joka ei selvinnyt korrelaatiomatriisista.
Liikevaihto suhteutettuna henkilöstöön, kaikkien veronalaisten tulojen mediaani, työttömyysaste sekä verovelvollisten lukumäärän logaritmi säilyttävät jo korrelaatiomatriisista nähdyt vaikutussuhteet. Kaiken muun ollessa vakiona miehet siis saavat suhteellisesti enemmän liksaa korkean tulotason, vähäisen työttömyyden ja ison väestöpohjan kunnissa, joiden yritykset takovat hyvää tulosta.
Yllä nähty malli toimii suhteellisen hyvin miesten ja naisten palkkaeron selittämisessä. Jäännöksiä tarkastellessa en havainnut mitään systemaattista virhettä ja mallilla korkea selitysaste. Mallin heikkous on sen muuttujien kollineariteettiongelmat, mutta käytettyäni Recursive Feature Elimination eli RFE-algoritmia valitsemaan optimaalisen selittävien muuttujien joukon, ei näiden perusteella tehty lopullinen malli poikennut juurikaan yllä nähdystä kaikki muuttujat sisältävästä mallista. Alla on vielä kuvaus ristiinvalidoinnin perusteella selitysvoimaisimmista muuttujista.

Järjestys oli nähtävissä jo regressiokertoimista.
Yllä olevasta tarkastelusta nähtiin, että miesten ja naisten palkkatuloissa on selkeitä alueellisia makrotason eroja. Tämä on suoraa seurausta erilaisten taloudellisten ekosysteemien ammattirakenteista sekä kuntien väestöpohjasta. Dynaamisissa, naisvoittoistuvissa kaupunkiyhteisöissä ja niiden lähikunnissa miehet tienaavat naisia paremmin, sillä niissä toistaiseksi "miehisillä" ammateilla pyyhkii hyvin ja miehet ovat perinteisesti olleet liike-elämän huipputehtävissä vahvemmin edustettuna. Miehistyvillä korkean työttömyyden syrjäseuduilla taas naiset pärjäävät paremmin, kun tarjontaa työpaikoista on vähemmän. Toisaalta muun ollessa vakioitu, naisten suhteellinen palkkataso paranee muuttovoittokunnissa, joissa naiset osallistuvat aktiivisemmin työelämään ja joissa on isompi maahanmuuttajapopulaatio.
Jos naisten ja miesten ansiotasoa halutaan aidosti kuroa umpeen, on lopetettava harhaanjohtava puhe "naisen euroista", joka luo mielikuvaa samassa työssä alhaisemmalla palkalla puurtavasta naisesta. Palkka on suhteellisen yksinkertaisesti mitattavissa oleva suure ja Milja Saaren sanoin "numeerisen kiistelyn" avulla voidaan saada informaatiota niistä seikoista, jotka aidosti aiheuttavat sukupuolten välillä havaittavaa eroa ansiotasossa. Ainoastaan validin faktaperustaisen tilastotieteellisen mallintamisen avulla voidaan kohdistaa huomio oikeisiin asioihin ja tehdä oikeita poliittisia päätöksiä.
Vanhemmuuden kulujen tasoittaminen on yksi helposti identifioitavissa oleva kehityskohde. Sukupuolittuneen ammattirakenteen purkaminen toinen. STTK: laisessa kielenkäytössä ymmärretty "palkkatasa-arvo", eli kahden sukupuolen yksilöiden palkkojen mediaanin täydellinen yhtäsuuruus riippumatta kaikista muista palkkaa selittävistä tekijöistä ei kuitenkaan ole maali, johon edes pitäisi pyrkiä.
Todellisuudessa miesten ja naisten saama palkkatulo samoista tehtävistä samanlaisella kokemuksella on lähes identtinen. Ei siis ole olemassa mitään 20 prosenttiyksikön mieslisää, jolla miehet tienaisivat samoista töistä enemmän kuin naiset. Sen sijaan sukupuolten välillä on eroja esimerkiksi ammattirakenteessa sekä tehdyissä työtunneissa, joiden vaikutukset saatuun palkkaan näyttäytyvät puusilmäisessä tarkastelussa sukupuolesta johtuvina palkkaeroina. Naisten ja miesten välinen ero ansiotuloissa on todellinen ja sisältää myös aitoja sukupuoli-perusteisia ongelmakohtia, joihin pitää puuttua. Mutta yksinkertaistamalla palkkaero binääriseksi kahden luokan väliseksi vertailuksi ilman muiden palkkaa selittävien muuttujien huomiointia kohdistuu huomio aivan vääriin asioihin.
Keskustelu palkkaerosta on siis usein aivan liian yksinkertaistettua eikä siinä huomioida mitään muuta kuin sukupuoli. Se on yhtä hedelmällistä kuin keskustella suomalaisten ja maahanmuuttajataustaisten rikollisuudesta käyttäen pelkästään etnisyyttä selittävänä tekijänä (maahanmuuttajat ovat esimerkiksi kantaväestöä nuorempia ja huono-osaisempia, mikä selittänee suuren osan havaituista eroista). Palkkaan vaikuttaa suuri määrä erilaisia muuttujia ja mikäli sukupuolten aitoa palkkaeroa halutaan tarkastella, tulee nämä taustatekijät ensiksi vakioida. Toisaalta jokainen tilastotiedettä vähänkin ymmärtävä tietää, että tarkasteluun valitut muuttujat muuttavat aina hieman tuloksia ja tehtäviä johtopäätöksiä, kuten Mika Malirantakin ansiokkaasti yllä linkkaamassani jutussa mainitsi. Siltikin mediassa paljon julkisuutta saaneen Milja Saaren väitöskirjassaan esittämä väite on huteralla pohjalla ja mielestäni suhteellisen heikko perusta tieteellisen tutkimuksen pohjaksi:
Aitoon keskusteluun palkkaeriarvoisuudesta, sen syistä, seurauksista ja samapalkkaisuuden toteuttamisen mahdollisuuksista on vaikea päästä, koska samapalkkaisuuskeskustelu tyrehtyy usein numeerisen kiistelyn tasolle: onko sukupuolten palkkaeroa olemassakaan, montako
prosenttia se on ja onko käytetty laskukaava tilastollisesti validi.
Mikrotasolla miesten ja naisten välistä palkkaeroa on tutkittu monen eri mallin voimin useaan kertaan, joista yksinkertaisin mallinnus on valitettavasti tunnetuin pelkän sukupuolen huomioiva"naisen euro"-päätelmä. Sen sijaan en ole aiemmin juuri törmännyt aiheen käsittelyyn rakenteellisella makrotasolla, jossa ihmisen asuinympäristö vaikuttaa myös sukupuolten väliseen tuloeroon. Tässä postauksessa tutkin miesten ja naisten palkkaeroa yksittäisten yksilöiden sijaan alueellisella makrotasolla; missä ja minkälaisissa kunnissa sukupuolten välinen ero palkkatuloissa on suurin?
Suomi on tunnetusti jakautunut voimakkaasti mies- ja naisaloihin ja ammatillinen segregaatio on EU:n kärkipäätä. Ammattijakauma on myös varsin poikkeava Suomen eri alueiden kesken, sillä esimerkiksi Kainuun perukoilla on huomattavasti vähemmän asiantuntijatehtäviä kuin suurissa kaupungeissa. Myös toimialarakenne tai esimerkiksi väestöllinen huoltosuhde ("vanhuskunnissa" tarvitaan enemmän naisvaltaisia hoitajia, joilla on yleisesti alhaiset palkat) ovat tekijöitä, jotka voivat makrotasolla johtaa suuriinkin kunnittaisiin eroihin eri sukupuolten ansiotasossa.
Aineistona minulla on Verohallinnon data päätoimen palkasta luontoisetuineen vuodelle 2014 (jaan vuoden kokonaispalkkatulot kahdellatoista, jotta saan approksimaation kuukausipalkasta) ja selittävinä muuttujina käytän logaritmia verovelvollisten määrästä (väestön määrän sijaan, logaritmi väestöjakauman vahvan vinouman vuoksi) sekä Tilastokeskukselta väestön koulutusmittaria (VKTM), työttömyystasoa, naisten työllisyysastetta, kuntien välistä muuttotasetta, väestöllistä huoltosuhdetta, ulkomaalaisten osuutta väestöstä sekä yritysten liikevaihtoa henkilöittäin.

Kun tuloerojen jakautumista tutkitaan alueittain niin huomataan, että hieman yllättäen tuloerot ovat suurimmat isoissa kaupungeissa ja niiden kehyskunnissa. Varsinkin Lapista löytyy toisaalta alueita, joissa naiset tienaavat miehiä paremmin. Kartan perusteella naisten suhteellinen asema miehiin nähden on paras syrjäseuduilla, joissa myös sukupuolten jakauma on vinoutunein miesten hyväksi ja jossa taloudellisia mahdollisuuksia on vähiten.
Naiset muodostavat yhä suuremman osan koulutetusta, urbaanista väestöstä, mutta suurituloisimmat ammatit näyttävät yhä olevan miesten hommia. Sen sijaan miehistyvällä maaseudulla vähät työpaikat jakautuvat tasaisemmin sukupuolten kesken, eikä kumpikaan sukupuoli saa suuria summia. Tutkitaan seuraavaksi miten valitut selittävät muuttujat korreloivat tuloerojen kanssa.
Korrelaatiomatriisista nähdään, että odotetusti selittävät muuttujat korreloivat melko voimakkaastikin keskenään, mikä tulee aiheuttamaan regressiomallissa kollineariteettiongelmia.
Miesten naisia suurempien tulojen kanssa korreloi voimakkaimmin yllä nähdyn kartan perusteella odotetusti kaikkien veronalaisten tulojen mediaani sekä väestön koulutustaso. Korkean tulotason ja koulutuksen sekä dynaamisen liike-elämän kunnissa myös sukupuolten väliset tuloerot venähtävät miesten hyväksi. Korkean työttömyyden ja heikon väestöllisen huoltosuhteen kunnissa taas naiset ovat suhteellisesti paremmin palkattuja. Ulkomaalaisten osuudella, muuttotaseella tai naisten työllisyysasteella ei näytä olevan juuri yhteyttä palkkatason eroon.
Kahden muuttujan välisten korrelaatioiden tarkastelu yksistään tarjoaa kuitenkin vääriä johtopäätöksiä jo mainittujen kollineariteettiongelmien vuoksi. Parempia johtopäätöksiä saadaan tehtyä, kun muiden selittävien muuttujien vaikutus palkkaeroon vakioidaan. Siksipä lopuksi mallinnan naisten ja miesten välistä palkkaeroa lineaarisen regression avulla. Skaalaan kaikki muuttujat yhteismitallisiksi, jotta muuttujien suhteellista selitysvoimaa ja tarkkuutta voidaan vertailla.
Residuals:
Min 1Q Median 3Q Max
-2.2624 -0.3517 0.0334 0.3055 3.9126
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -7.749e-16 3.534e-02 0.000 1.00000
tyottomyysaste 1.090e+00 9.995e-02 10.909 < 2e-16 ***
muuttotase 1.253e-01 3.951e-02 3.172 0.00167 **
VKTM -7.548e-02 7.454e-02 -1.013 0.31203
tyollisyysasteNaiset 9.063e-01 9.124e-02 9.933 < 2e-16 ***
verovelvollisia -1.436e-01 5.765e-02 -2.491 0.01327 *
liikevaihtoperhenkilo -9.112e-02 4.152e-02 -2.194 0.02897 *
ulkomOsuus 2.296e-01 4.490e-02 5.113 5.62e-07 ***
huoltosuhde -4.618e-02 5.811e-02 -0.795 0.42747
tulotYht -4.330e-01 7.698e-02 -5.625 4.23e-08 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.6253 on 303 degrees of freedom
Multiple R-squared: 0.6203, Adjusted R-squared: 0.609
F-statistic: 54.99 on 9 and 303 DF, p-value: < 2.2e-16
Ylläolevasta regressiotaulukosta nähdään, että malli on tilastollisesti merkitsevä ja selittää jopa 61 % miesten ja naisten alueellisessa palkkaerossa havaitusta vaihtelusta. Vakiotermi ei mallissa ole tilastollisesti merkitsevä, kuten ei myöskään väestön koulutustaso ja väestöllinen huoltosuhde. Nämä kaksi muuttujaa kuitenkin korreloivat vahvasti palkkaeron kanssa, mutta niiden korrelaatio myös muiden selittävien muuttujien kanssa vei niiden selitysvoiman kun työttömyysaste ja muut tekijät vakioitiin. Sen sijaan ulkomaalaisten osuus kunnan väestöstä esiintyykin voimakkaasti selitysvoimaisena muuttjana muiden selittävien muuttujien ollessa vakioitu. Muiden muuttujien ollessa vakioitu, korkeampi ulkomaalaisten osuus tarkoittaa naisille suhteellisesti parempaa palkkaa.
Myös muuttotase muuttuu tilastollisesti merkitseväksi selittäjäksi, kun muut selittävät muuttujat vakioidaan. Muuttovoittokunnissa naisten palkkaus vaikuttaisi olevan suhteellisesti parempaa. Kun muuttotasetta korreloitiin pelkän palkkaeron kanssa, vaikutussuhde oli päinvastainen. Muun ollessa vakiona myös naisten korkeampi työllisyysaste vaikuttaa voimakkaasti palkkaeroihin naisten kannalta suotuisasti. Tämä on hyvin looginen johtopäätös, joka ei selvinnyt korrelaatiomatriisista.
Liikevaihto suhteutettuna henkilöstöön, kaikkien veronalaisten tulojen mediaani, työttömyysaste sekä verovelvollisten lukumäärän logaritmi säilyttävät jo korrelaatiomatriisista nähdyt vaikutussuhteet. Kaiken muun ollessa vakiona miehet siis saavat suhteellisesti enemmän liksaa korkean tulotason, vähäisen työttömyyden ja ison väestöpohjan kunnissa, joiden yritykset takovat hyvää tulosta.
Yllä nähty malli toimii suhteellisen hyvin miesten ja naisten palkkaeron selittämisessä. Jäännöksiä tarkastellessa en havainnut mitään systemaattista virhettä ja mallilla korkea selitysaste. Mallin heikkous on sen muuttujien kollineariteettiongelmat, mutta käytettyäni Recursive Feature Elimination eli RFE-algoritmia valitsemaan optimaalisen selittävien muuttujien joukon, ei näiden perusteella tehty lopullinen malli poikennut juurikaan yllä nähdystä kaikki muuttujat sisältävästä mallista. Alla on vielä kuvaus ristiinvalidoinnin perusteella selitysvoimaisimmista muuttujista.

Yllä olevasta tarkastelusta nähtiin, että miesten ja naisten palkkatuloissa on selkeitä alueellisia makrotason eroja. Tämä on suoraa seurausta erilaisten taloudellisten ekosysteemien ammattirakenteista sekä kuntien väestöpohjasta. Dynaamisissa, naisvoittoistuvissa kaupunkiyhteisöissä ja niiden lähikunnissa miehet tienaavat naisia paremmin, sillä niissä toistaiseksi "miehisillä" ammateilla pyyhkii hyvin ja miehet ovat perinteisesti olleet liike-elämän huipputehtävissä vahvemmin edustettuna. Miehistyvillä korkean työttömyyden syrjäseuduilla taas naiset pärjäävät paremmin, kun tarjontaa työpaikoista on vähemmän. Toisaalta muun ollessa vakioitu, naisten suhteellinen palkkataso paranee muuttovoittokunnissa, joissa naiset osallistuvat aktiivisemmin työelämään ja joissa on isompi maahanmuuttajapopulaatio.
Jos naisten ja miesten ansiotasoa halutaan aidosti kuroa umpeen, on lopetettava harhaanjohtava puhe "naisen euroista", joka luo mielikuvaa samassa työssä alhaisemmalla palkalla puurtavasta naisesta. Palkka on suhteellisen yksinkertaisesti mitattavissa oleva suure ja Milja Saaren sanoin "numeerisen kiistelyn" avulla voidaan saada informaatiota niistä seikoista, jotka aidosti aiheuttavat sukupuolten välillä havaittavaa eroa ansiotasossa. Ainoastaan validin faktaperustaisen tilastotieteellisen mallintamisen avulla voidaan kohdistaa huomio oikeisiin asioihin ja tehdä oikeita poliittisia päätöksiä.
Vanhemmuuden kulujen tasoittaminen on yksi helposti identifioitavissa oleva kehityskohde. Sukupuolittuneen ammattirakenteen purkaminen toinen. STTK: laisessa kielenkäytössä ymmärretty "palkkatasa-arvo", eli kahden sukupuolen yksilöiden palkkojen mediaanin täydellinen yhtäsuuruus riippumatta kaikista muista palkkaa selittävistä tekijöistä ei kuitenkaan ole maali, johon edes pitäisi pyrkiä.
lauantai 8. lokakuuta 2016
Mistä Suomi(24) puhuu nyt?
Suomi24 lienee jokaisen tuntema ajatusten kaatopaikka, joka Suomen suurimpana keskustelupalstana tarjoaa mielipiteitä jokaiseen mahdolliseen ja mahdottomaan asiaan. Suomi24:n aineistot on jo aikaisemmin avattu tutkimuskäyttöön ja aineisto tarjoaakin hedelmällisen aineiston monien elämänalojen tutkimiseen ja niin politologit kuin sosiologitkin ovat varmasti saaneet datasta paljon irti.
Minulla ei tuota aineistoa ole käytössäni, joten harjoitan oman aineistoni keräämiseksi ns. "web scrapingia" eli datan imemistä suoraan nettisivuilta. Toimin niin, että valitsen ylätason aihealueen (tässä postauksessa keskityn pääasiassa yhteiskunta/politiikka-otsakkeen alta löytyviin topiceihin) ja käyn lukemassa otsakkeen alta löytyvien noin 20 viimeisen topikin jokaisen viestin.
Mistä siis Suomi24 tällä hetkellä puhuu?

Lyhyt vastaus: työstä ja poliittisesta vasemmistosta, suhteessa Ruotsiin.
Selkeästi Martti Ahtisaaren uusi kirja, jossa tasavallan presidentti hyökkäsi vanhaa puoluettaan Demareita sekä ay-liikettä vastaan kovasanaisesti on saanut paljon keskustelua aikaan myös Suomen epävirallisella agoralla. Li Andersson on myös on näkyvästi esillä Suomi24:n talouspoliittiseen ja vasemmistoon tällä hetkellä keskittyvässä diskurssissa ja ainoa poliitikko pääministeri Sipilän ja Ahtisaaren lisäksi, joka pääsee 150 yleisimmän sanan joukkoon. Oppositiojohtajana Li nauttii siis tällä hetkellä huomattavasti todellista valtaansa parempaa näkyvyttä Suomi24:n poliittisessa keskustelussa.
Sanapilvestä ei ole oikeastaan havaittavissa kuin kaksi suurta teemaa, työpolitiikka/ay-liike/vasemmisto ja suomi/ruotsi-vertailu. Aineisto kuitenkin aidosti jakautuu hienovaraisempiin aihepiireihin, joiden pitäisi karkeasti noudattaa niitä 22 otsaketta, joiden alta aineisto on haettu. Kokeilen siis seuraavaksi löytää algoritmien avulla hienovaraisempia aihepiirejä, joihin aineisto jakaantuu.
 Hyvä lähtökohta hienovaraisempaan jaotteluun on tehdä visuaalinen hierarkinen klusterointi, joka näkyy yllä.
Hyvä lähtökohta hienovaraisempaan jaotteluun on tehdä visuaalinen hierarkinen klusterointi, joka näkyy yllä.
Data jakaantuu algoritmin mukaan hyvin rankasti yhteen homogeeniseen joukkoon tekstejä sekä toiseen ryhmittymään, josta hienovaraisempia jaotteluja on havaittavissa. Dendrogramin pohjalta onkin hyvä kehittää jatkotarkastelua. Hierarkinen klusterointi kun itsessään ei ole paras mahdollinen tekstimuotoisen datan ryhmittelijä. Latent Dirichlet Allocation on menetelmä, joka on optimoitu toimimaan tekstimuotoisen datan kanssa. Siinä yhtä dokumenttia (tässä tapauksessa viestiä politiikka-aiheiseen topikkiin) ei luokitella yhteen ja vain yhteen aihepiiriin (klusteriin, kuten yllä) vaan yhden viestin sallitaan sisältään useita eri aihepiirejä eri painotuksilla. Erona hierarkiseen klusteriin aihepiirien lukumäärä k täytyy päättää ennalta, kuten k means klusteroinnissakin.
Hierarkisen klusteroinnin perusteella päädyin valitsemaan parametrin k arvoksi 7. Alla on taulukko jokaiseen aihepiiriin 15 vahvimmin latautuvasta sanasta.
Ensimmäinen aihepiiri liittyy työhön ja erityisesti palkanmaksuun. Ja minimipalkasta puhuttaessa myös Vasemmistoliitto on näkyvästi läsnä. Toinen aihepiiri taas liittyy Martti Ahtisaaren kirjaan, mutta kirjan sisältämät teemat eivät ole näkyvästi esillä. Metsään ilmeisesti kuitenkin mennään Martin ay-liikkeen ja demarien kritisoinnissa.
Kolmas aihepiiri liittyy yrittämiseen ja itsensätyöllistämiseen ja on siten myös vahvasti työhön liittyvä aihepiiri. Neljäs on Li Anderssonille ja Vasemmistoliitolle omistettu aihepiiri, jossa myös vähemmän sosialistisempi työväenpuolue SDP mainitaan. Aihepiirit 5 ja 6 ovat vaikeammin pääteltävissä. Kuudennessa mainitaan Soini, joten liittynee etäisestä perussuomalaisiin. Viimeinen ja seitsemäs aineistosta löydetty aihepiiri taas liittyy iki-ihanaan vertailuun Suomen ja ruotsalaisten välillä. Mistä aiheesta siinä puhutaan, en tiedä, kunhan ruotsalaiset todetaan huonommiksi.
Aineistosta havaitaan taas tarve laadukkaalle suomenkieliselle stemmerille eli algoritmille, joka muuttaa sanat perusmuotoonsa. Tässäkin aineistoissa Suomi mainitaan lähes jokaisessa mahdollisessa sijamuodossa. Tästä huolimatta saamme ihan kelvollisen kuvan tämän hetken suomi24:sta puhuttavista aiheista.
Minulla ei tuota aineistoa ole käytössäni, joten harjoitan oman aineistoni keräämiseksi ns. "web scrapingia" eli datan imemistä suoraan nettisivuilta. Toimin niin, että valitsen ylätason aihealueen (tässä postauksessa keskityn pääasiassa yhteiskunta/politiikka-otsakkeen alta löytyviin topiceihin) ja käyn lukemassa otsakkeen alta löytyvien noin 20 viimeisen topikin jokaisen viestin.
Mistä siis Suomi24 tällä hetkellä puhuu?

Lyhyt vastaus: työstä ja poliittisesta vasemmistosta, suhteessa Ruotsiin.
Selkeästi Martti Ahtisaaren uusi kirja, jossa tasavallan presidentti hyökkäsi vanhaa puoluettaan Demareita sekä ay-liikettä vastaan kovasanaisesti on saanut paljon keskustelua aikaan myös Suomen epävirallisella agoralla. Li Andersson on myös on näkyvästi esillä Suomi24:n talouspoliittiseen ja vasemmistoon tällä hetkellä keskittyvässä diskurssissa ja ainoa poliitikko pääministeri Sipilän ja Ahtisaaren lisäksi, joka pääsee 150 yleisimmän sanan joukkoon. Oppositiojohtajana Li nauttii siis tällä hetkellä huomattavasti todellista valtaansa parempaa näkyvyttä Suomi24:n poliittisessa keskustelussa.
Sanapilvestä ei ole oikeastaan havaittavissa kuin kaksi suurta teemaa, työpolitiikka/ay-liike/vasemmisto ja suomi/ruotsi-vertailu. Aineisto kuitenkin aidosti jakautuu hienovaraisempiin aihepiireihin, joiden pitäisi karkeasti noudattaa niitä 22 otsaketta, joiden alta aineisto on haettu. Kokeilen siis seuraavaksi löytää algoritmien avulla hienovaraisempia aihepiirejä, joihin aineisto jakaantuu.

Data jakaantuu algoritmin mukaan hyvin rankasti yhteen homogeeniseen joukkoon tekstejä sekä toiseen ryhmittymään, josta hienovaraisempia jaotteluja on havaittavissa. Dendrogramin pohjalta onkin hyvä kehittää jatkotarkastelua. Hierarkinen klusterointi kun itsessään ei ole paras mahdollinen tekstimuotoisen datan ryhmittelijä. Latent Dirichlet Allocation on menetelmä, joka on optimoitu toimimaan tekstimuotoisen datan kanssa. Siinä yhtä dokumenttia (tässä tapauksessa viestiä politiikka-aiheiseen topikkiin) ei luokitella yhteen ja vain yhteen aihepiiriin (klusteriin, kuten yllä) vaan yhden viestin sallitaan sisältään useita eri aihepiirejä eri painotuksilla. Erona hierarkiseen klusteriin aihepiirien lukumäärä k täytyy päättää ennalta, kuten k means klusteroinnissakin.
Hierarkisen klusteroinnin perusteella päädyin valitsemaan parametrin k arvoksi 7. Alla on taulukko jokaiseen aihepiiriin 15 vahvimmin latautuvasta sanasta.
Ensimmäinen aihepiiri liittyy työhön ja erityisesti palkanmaksuun. Ja minimipalkasta puhuttaessa myös Vasemmistoliitto on näkyvästi läsnä. Toinen aihepiiri taas liittyy Martti Ahtisaaren kirjaan, mutta kirjan sisältämät teemat eivät ole näkyvästi esillä. Metsään ilmeisesti kuitenkin mennään Martin ay-liikkeen ja demarien kritisoinnissa.
Kolmas aihepiiri liittyy yrittämiseen ja itsensätyöllistämiseen ja on siten myös vahvasti työhön liittyvä aihepiiri. Neljäs on Li Anderssonille ja Vasemmistoliitolle omistettu aihepiiri, jossa myös vähemmän sosialistisempi työväenpuolue SDP mainitaan. Aihepiirit 5 ja 6 ovat vaikeammin pääteltävissä. Kuudennessa mainitaan Soini, joten liittynee etäisestä perussuomalaisiin. Viimeinen ja seitsemäs aineistosta löydetty aihepiiri taas liittyy iki-ihanaan vertailuun Suomen ja ruotsalaisten välillä. Mistä aiheesta siinä puhutaan, en tiedä, kunhan ruotsalaiset todetaan huonommiksi.
Aineistosta havaitaan taas tarve laadukkaalle suomenkieliselle stemmerille eli algoritmille, joka muuttaa sanat perusmuotoonsa. Tässäkin aineistoissa Suomi mainitaan lähes jokaisessa mahdollisessa sijamuodossa. Tästä huolimatta saamme ihan kelvollisen kuvan tämän hetken suomi24:sta puhuttavista aiheista.
Tilaa:
Kommentit (Atom)